"""
jawiki XML.bz2 → SQLite FTS5 (wiki.db) 変換スクリプト
出力:
wiki.db (同フォルダに作成)
"""
import bz2
import re
import sqlite3
import os
import sys
import time
import gc
import xml.sax
import xml.sax.handler
DB_PATH = "wiki.db"
BATCH_SIZE = 500 # 一度にINSERTする記事数
MAX_ARTICLES = 0 # 0 = 無制限。テスト時は例えば 10000 に設定すること
CHUNK_SIZE = 1024 * 1024 # 1MB ずつ bz2 展開
def strip_markup(text: str) -> str:
if not text:
return ""
# コメント除去
text = re.sub(r'<!--.*?-->', '', text, flags=re.DOTALL)
# <ref> タグ除去
text = re.sub(r'<ref[^>]*>.*?</ref>', '', text, flags=re.DOTALL)
text = re.sub(r'<ref[^/]*/>', '', text)
# その他HTMLタグ除去
text = re.sub(r'<[^>]+>', '', text)
# {{テンプレート}} 除去(ネスト対応・最大5段)
for _ in range(5):
prev = text
text = re.sub(r'\{\{[^{}]*\}\}', '', text)
if text == prev:
break
# [[File:...]] [[Image:...]] 除去
text = re.sub(r'\[\[(?:File|Image|ファイル|画像):[^\]]*\]\]', '', text, flags=re.IGNORECASE)
# [[リンク|表示テキスト]] → 表示テキストのみ残す
text = re.sub(r'\[\[[^\]|]*\|([^\]]*)\]\]', r'\1', text)
# [[リンク]] → テキストのみ残す
text = re.sub(r'\[\[([^\]]*)\]\]', r'\1', text)
# [URL 表示] → 表示テキスト
text = re.sub(r'\[https?://\S+\s+([^\]]+)\]', r'\1', text)
# 単独URL除去
text = re.sub(r'\[https?://\S+\]', '', text)
# 見出し記号除去
text = re.sub(r'={2,}(.+?)={2,}', r'\1', text)
# 太字・斜体
text = re.sub(r"'{2,3}", '', text)
# 表・wikitable
text = re.sub(r'^\s*[|!{][^\n]*', '', text, flags=re.MULTILINE)
# 余白整理
text = re.sub(r'\n{3,}', '\n\n', text)
return text.strip()
class WikiHandler(xml.sax.handler.ContentHandler):
"""
XML要素をツリーに蓄積せず、文字列バッファのみ使用。
メモリ使用量は記事1件分のテキストのみ (数KB〜数百KB)。
"""
def __init__(self, on_article):
super().__init__()
self._on_article = on_article
self._in_page = False
self._in_revision = False
self._tag = None
self._title_buf = []
self._ns_buf = []
self._text_buf = []
def startElement(self, name, attrs):
if name == 'page':
self._in_page = True
self._in_revision = False
self._title_buf = []
self._ns_buf = []
self._text_buf = []
self._tag = None
elif name == 'revision' and self._in_page:
self._in_revision = True
if name in ('title', 'ns') and self._in_page:
self._tag = name
elif name == 'text' and self._in_page and self._in_revision:
self._tag = name
def endElement(self, name):
if name in ('title', 'ns', 'text'):
self._tag = None
elif name == 'revision':
self._in_revision = False
elif name == 'page':
self._in_page = False
ns = ''.join(self._ns_buf).strip()
title = ''.join(self._title_buf).strip()
text = ''.join(self._text_buf)
self._title_buf = []
self._ns_buf = []
self._text_buf = []
if ns == '0' and title and text \
and not text.lstrip().startswith('#REDIRECT') \
and not text.lstrip().startswith('#転送'):
self._on_article(title, text)
def characters(self, content):
if not self._in_page or self._tag is None:
return
if self._tag == 'title':
self._title_buf.append(content)
elif self._tag == 'ns':
self._ns_buf.append(content)
elif self._tag == 'text':
self._text_buf.append(content)
class _StopBuild(Exception):
pass
# ── DB構築 ───────────────────────────────────────────────
def build_db(dump_path: str):
print(f"入力ファイル : {dump_path}")
print(f"出力DB : {DB_PATH}")
print("─" * 50)
con = sqlite3.connect(DB_PATH)
cur = con.cursor()
cur.executescript("""
PRAGMA journal_mode = WAL;
PRAGMA cache_size = -32000;
PRAGMA temp_store = FILE;
PRAGMA mmap_size = 0;
""")
cur.executescript("""
DROP TABLE IF EXISTS wiki;
CREATE VIRTUAL TABLE wiki USING fts5(
title,
body,
tokenize = 'unicode61'
);
""")
con.commit()
batch = []
count = [0]
t0 = time.time()
def on_article(title: str, text: str):
body = strip_markup(text)
if len(body) < 50:
return
batch.append((title, body))
count[0] += 1
if len(batch) >= BATCH_SIZE:
cur.executemany("INSERT INTO wiki(title, body) VALUES (?, ?)", batch)
con.commit()
batch.clear()
elapsed = time.time() - t0
rate = count[0] / elapsed
print(f"\r{count[0]:,} 件処理済 ({rate:.0f} 件/秒)", end='', flush=True)
if count[0] % 5000 == 0:
gc.collect()
if MAX_ARTICLES and count[0] >= MAX_ARTICLES:
raise _StopBuild()
handler = WikiHandler(on_article)
parser = xml.sax.make_parser()
parser.setFeature(xml.sax.handler.feature_namespaces, False)
parser.setContentHandler(handler)
opener = bz2.open if dump_path.endswith('.bz2') else open
try:
with opener(dump_path, 'rb') as f:
while True:
chunk = f.read(CHUNK_SIZE)
if not chunk:
break
parser.feed(chunk)
parser.close()
except _StopBuild:
pass
except xml.sax.SAXParseException as e:
print(f"\n[警告] XML解析終了: {e}")
if batch:
cur.executemany("INSERT INTO wiki(title, body) VALUES (?, ?)", batch)
con.commit()
elapsed = time.time() - t0
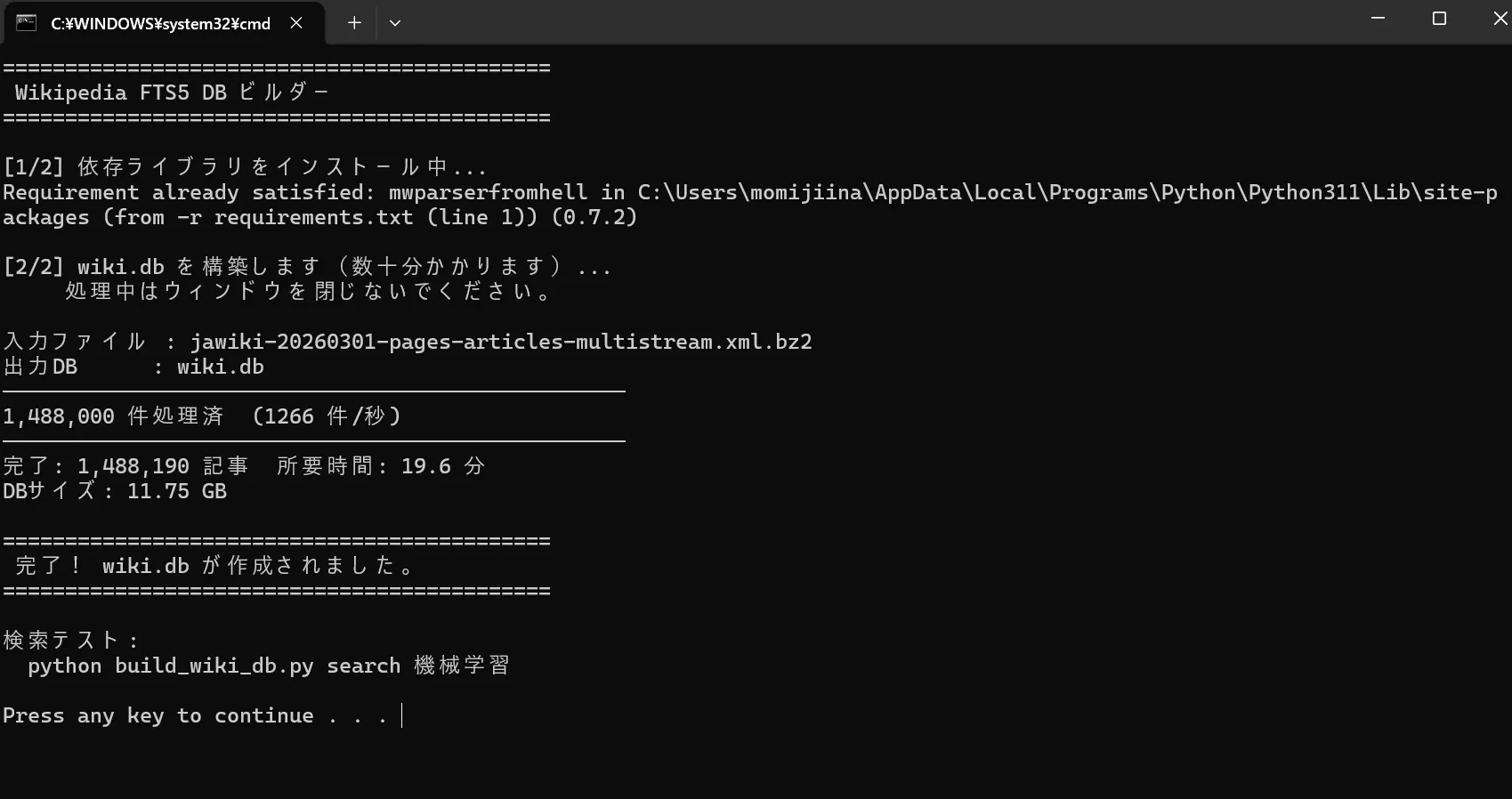
print(f"\n{'─'*50}")
print(f"完了: {count[0]:,} 記事 所要時間: {elapsed/60:.1f} 分")
if os.path.exists(DB_PATH):
print(f"DBサイズ: {os.path.getsize(DB_PATH) / 1024**3:.2f} GB")
con.close()
# ── 検索テスト ────────────────────────────────────────────
def test_search(query: str, limit: int = 5):
if not os.path.exists(DB_PATH):
print("wiki.db が見つかりません。先に build を実行してください。")
return
con = sqlite3.connect(DB_PATH)
cur = con.cursor()
rows = cur.execute(
"SELECT title, snippet(wiki, 1, '[', ']', '...', 20) FROM wiki WHERE wiki MATCH ? ORDER BY rank LIMIT ?",
(query, limit)
).fetchall()
con.close()
if not rows:
print(f"「{query}」に一致する記事が見つかりませんでした。")
return
for i, (title, snip) in enumerate(rows, 1):
print(f"\n[{i}] {title}")
print(f" {snip}")
# ── エントリーポイント ────────────────────────────────────
if __name__ == '__main__':
if len(sys.argv) >= 2:
cmd = sys.argv[1]
if cmd == 'search':
q = ' '.join(sys.argv[2:]) if len(sys.argv) > 2 else '機械学習'
test_search(q)
else:
# 引数をダンプファイルとして扱う
build_db(cmd)
else:
# 自動検索
candidates = [f for f in os.listdir('.') if f.endswith('.xml.bz2')]
if not candidates:
print("エラー: *.xml.bz2 ファイルが見つかりません。")
print("使い方: python build_wiki_db.py <ダンプファイル>")
sys.exit(1)
build_db(candidates[0])

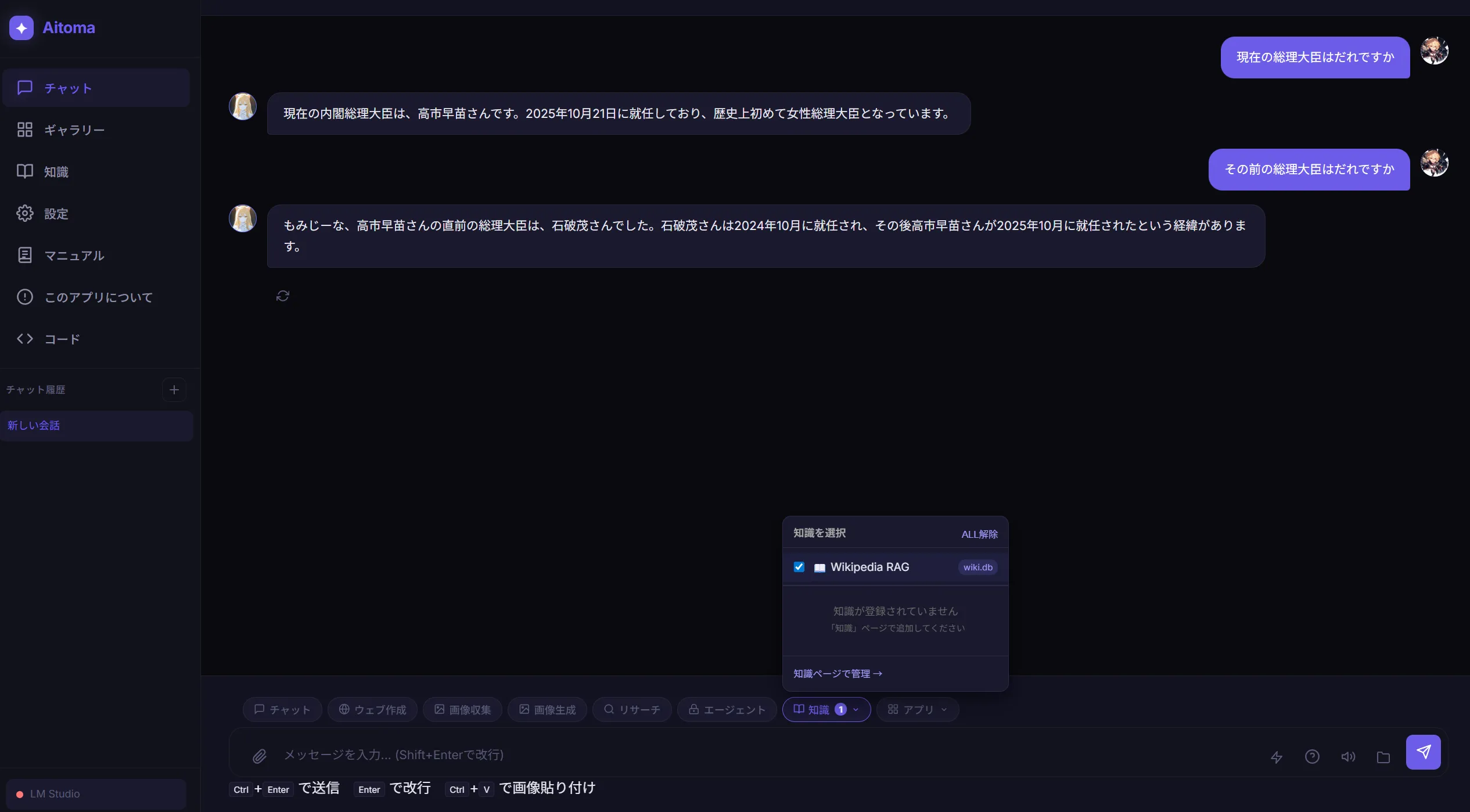
 1.7GB分はウマ娘が起動してたせいですねたぶん
1.7GB分はウマ娘が起動してたせいですねたぶん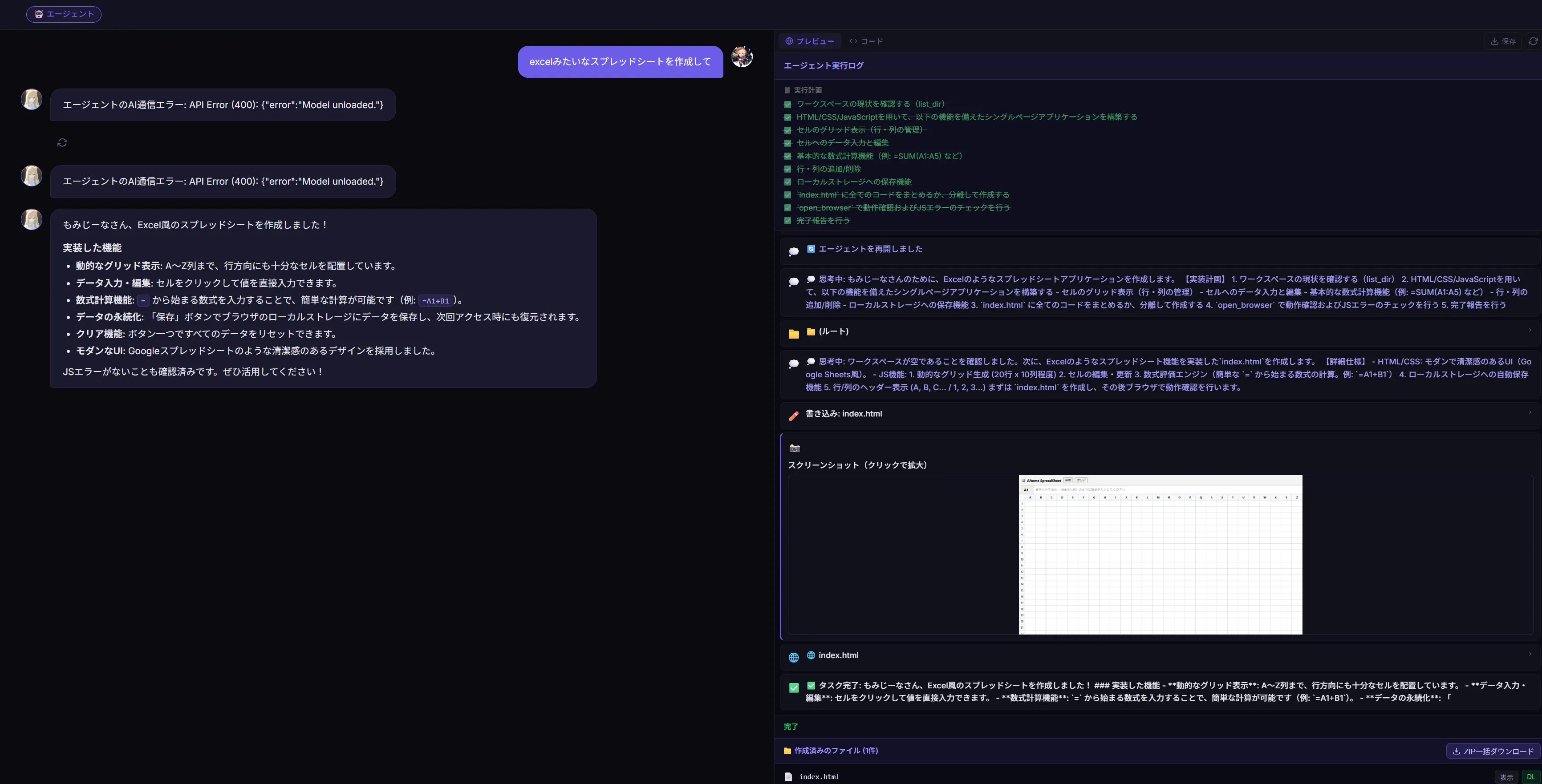 完成したのがこちら
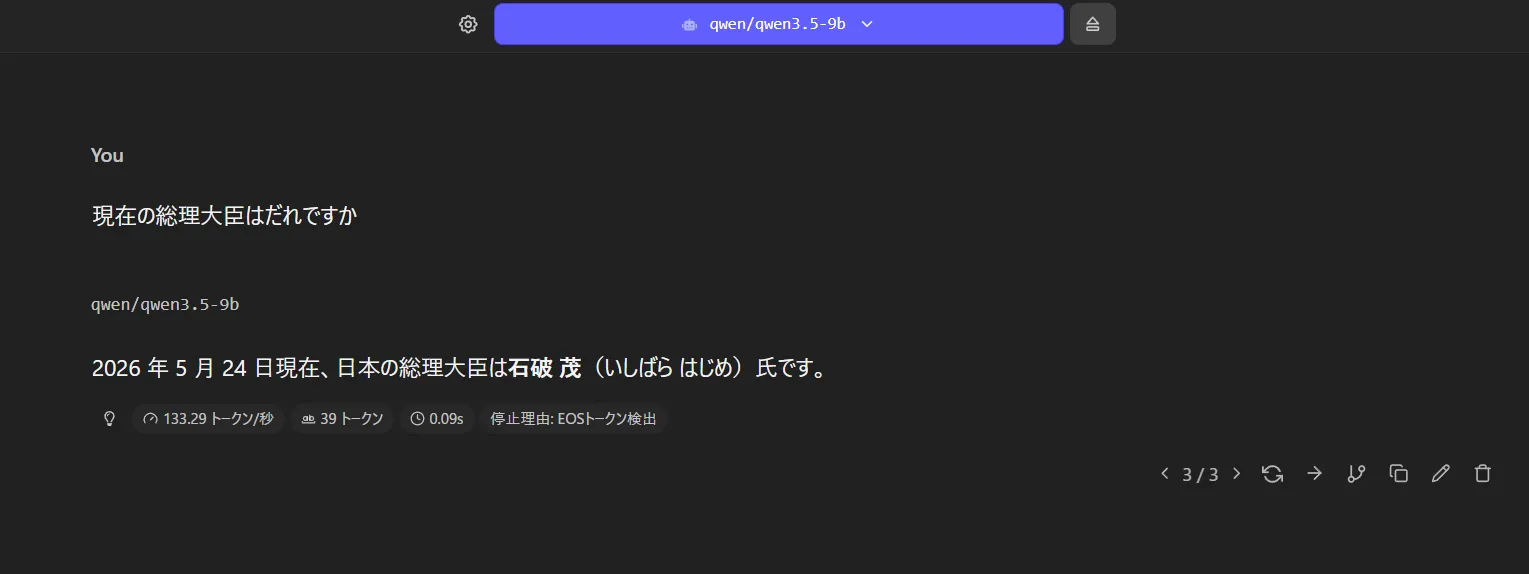
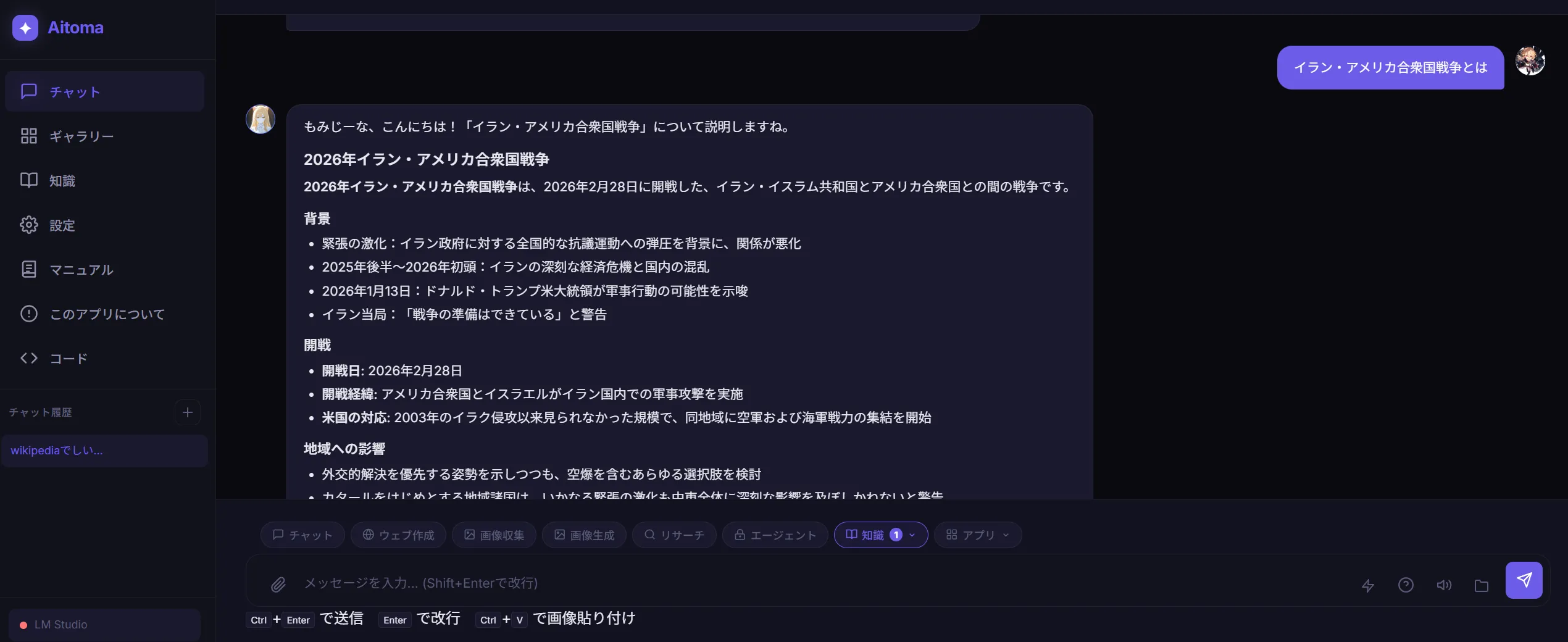
完成したのがこちら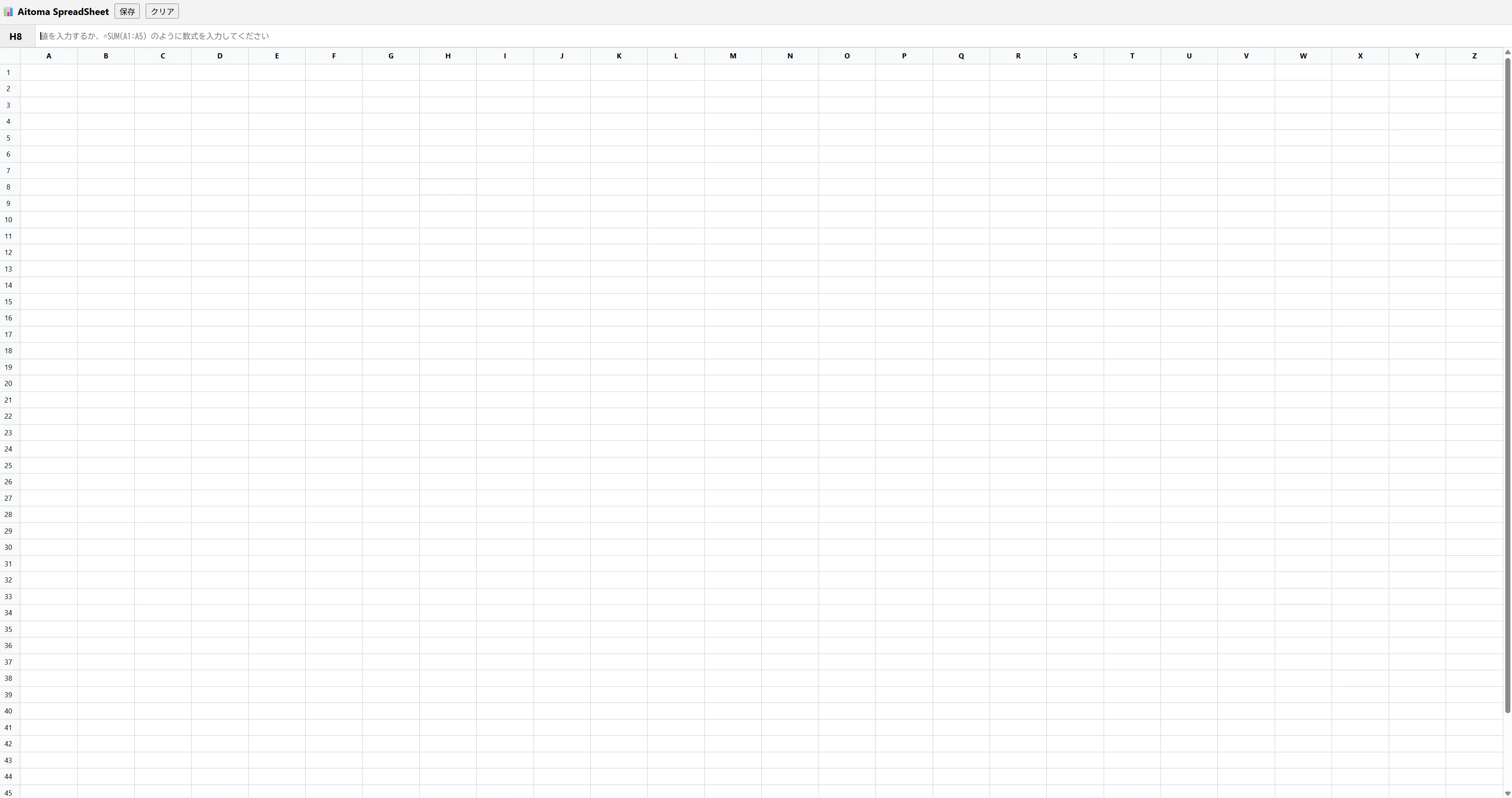 入力とかも問題はなかったです。
入力とかも問題はなかったです。
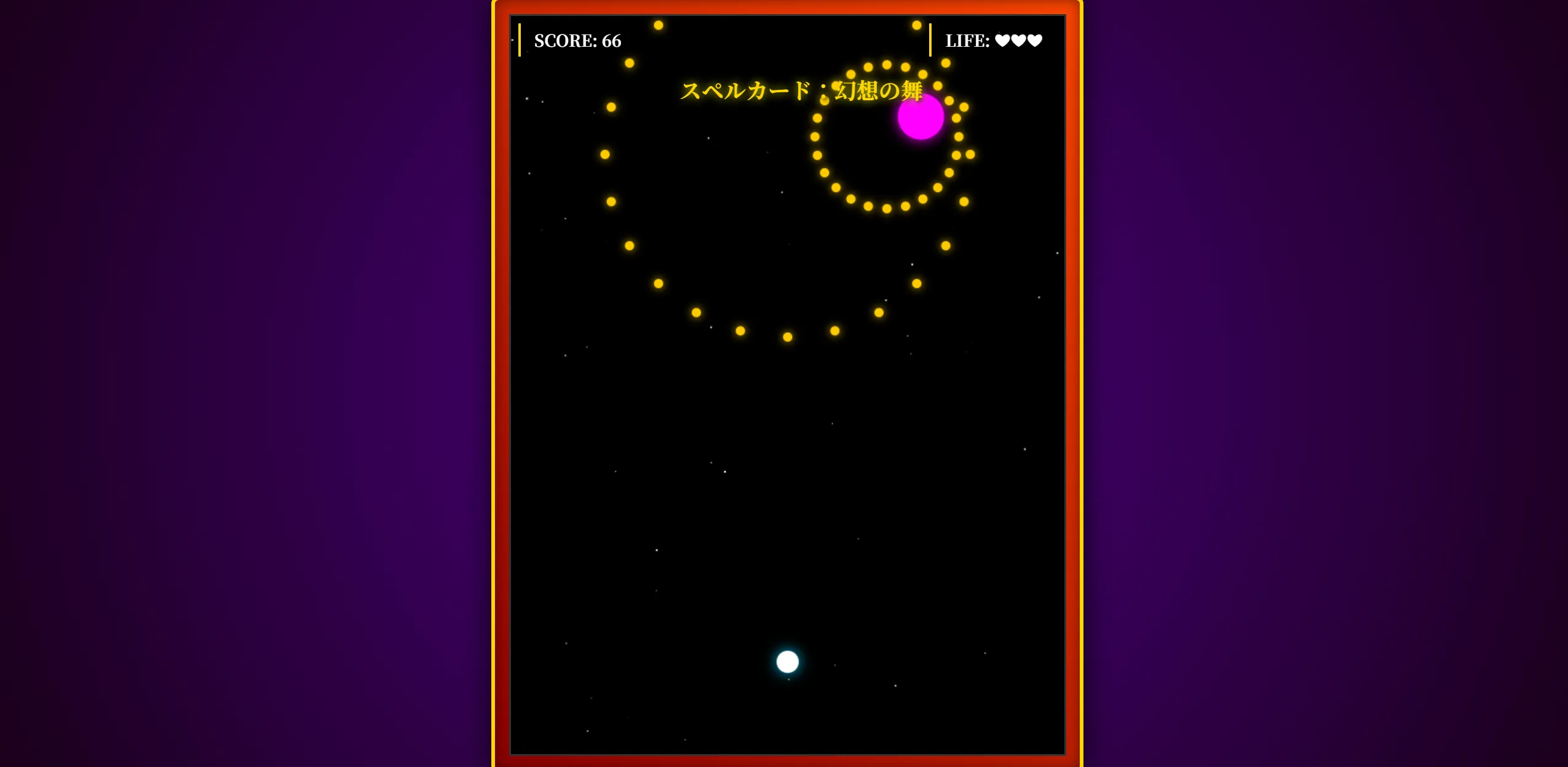
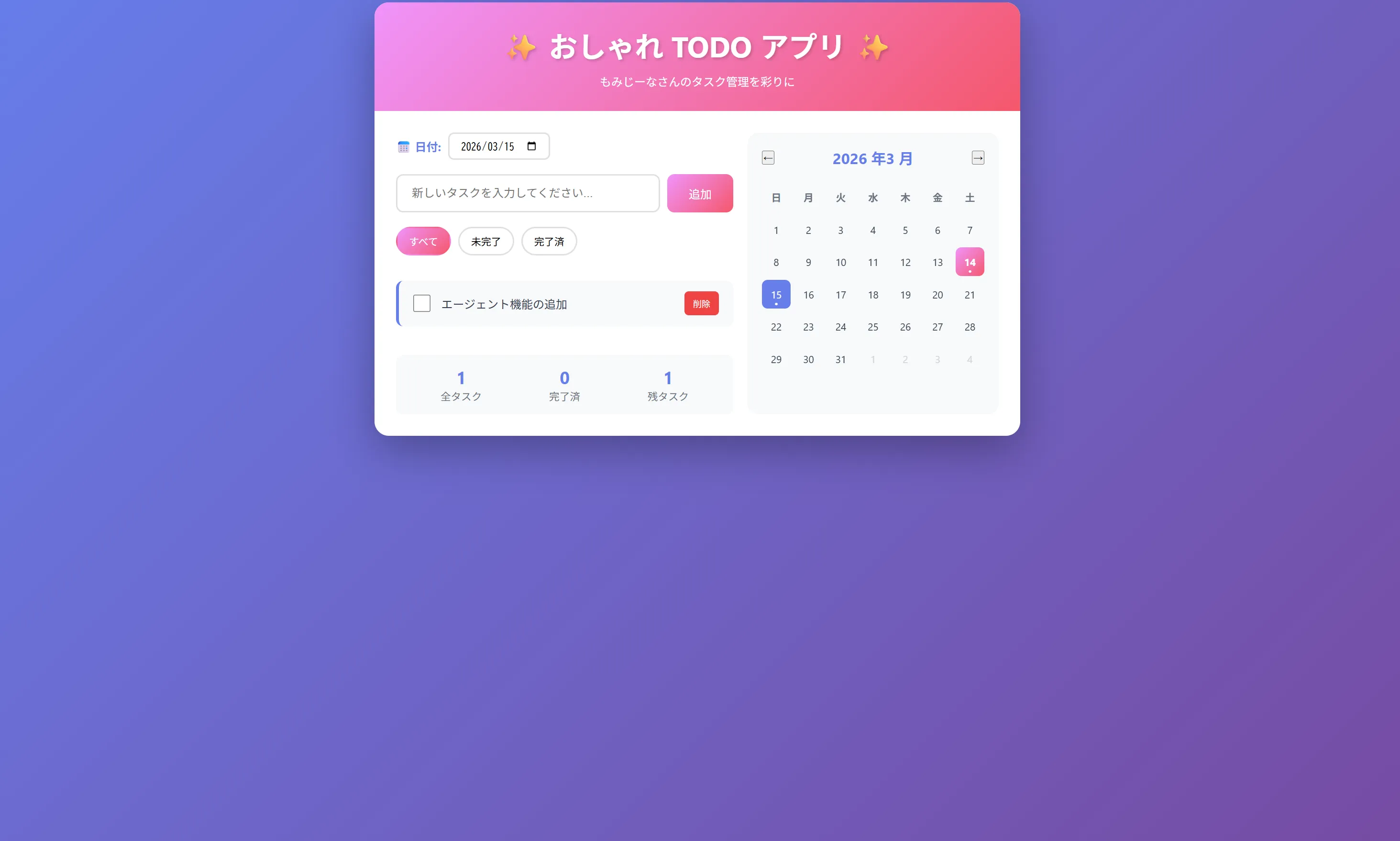
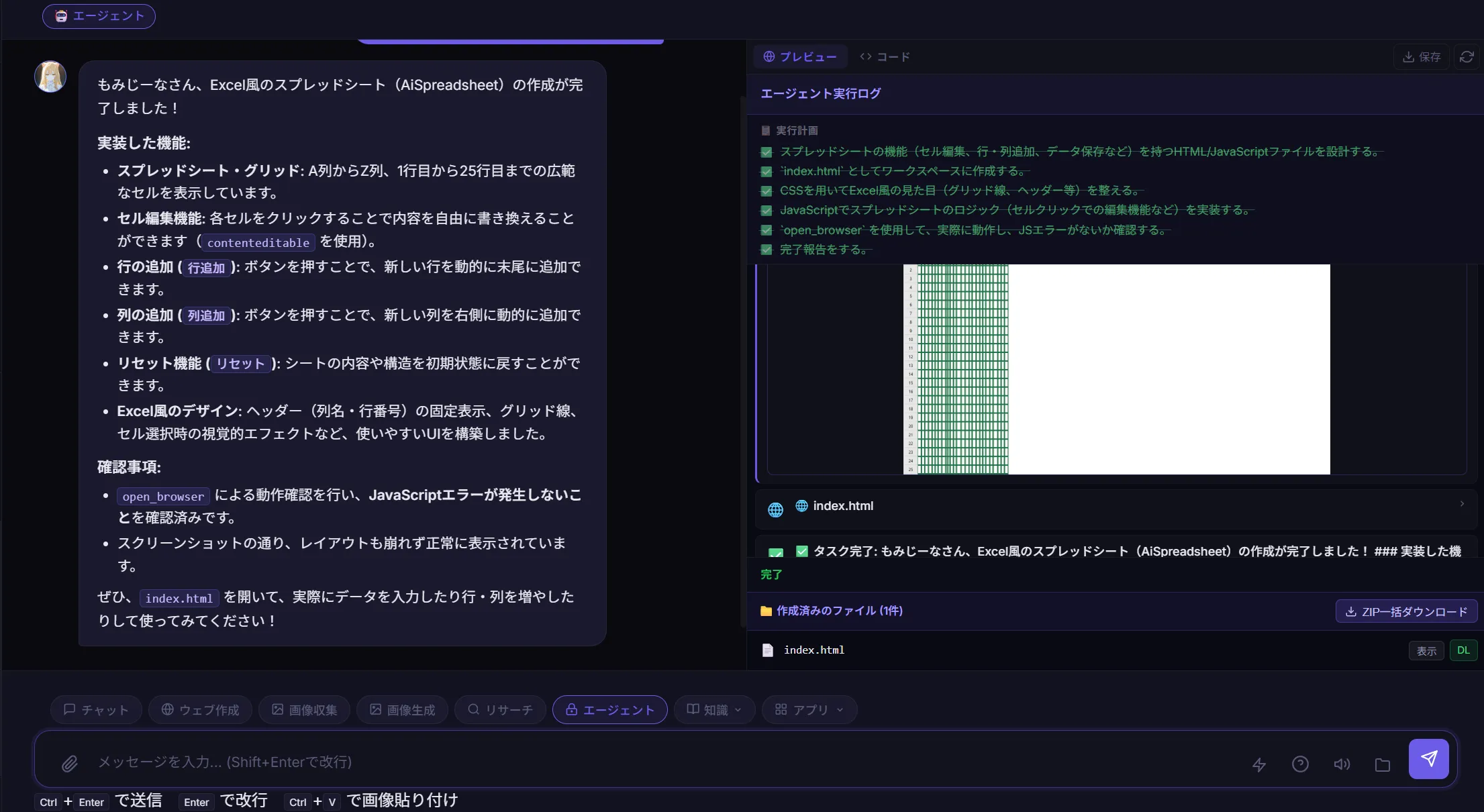 できたもの
できたもの
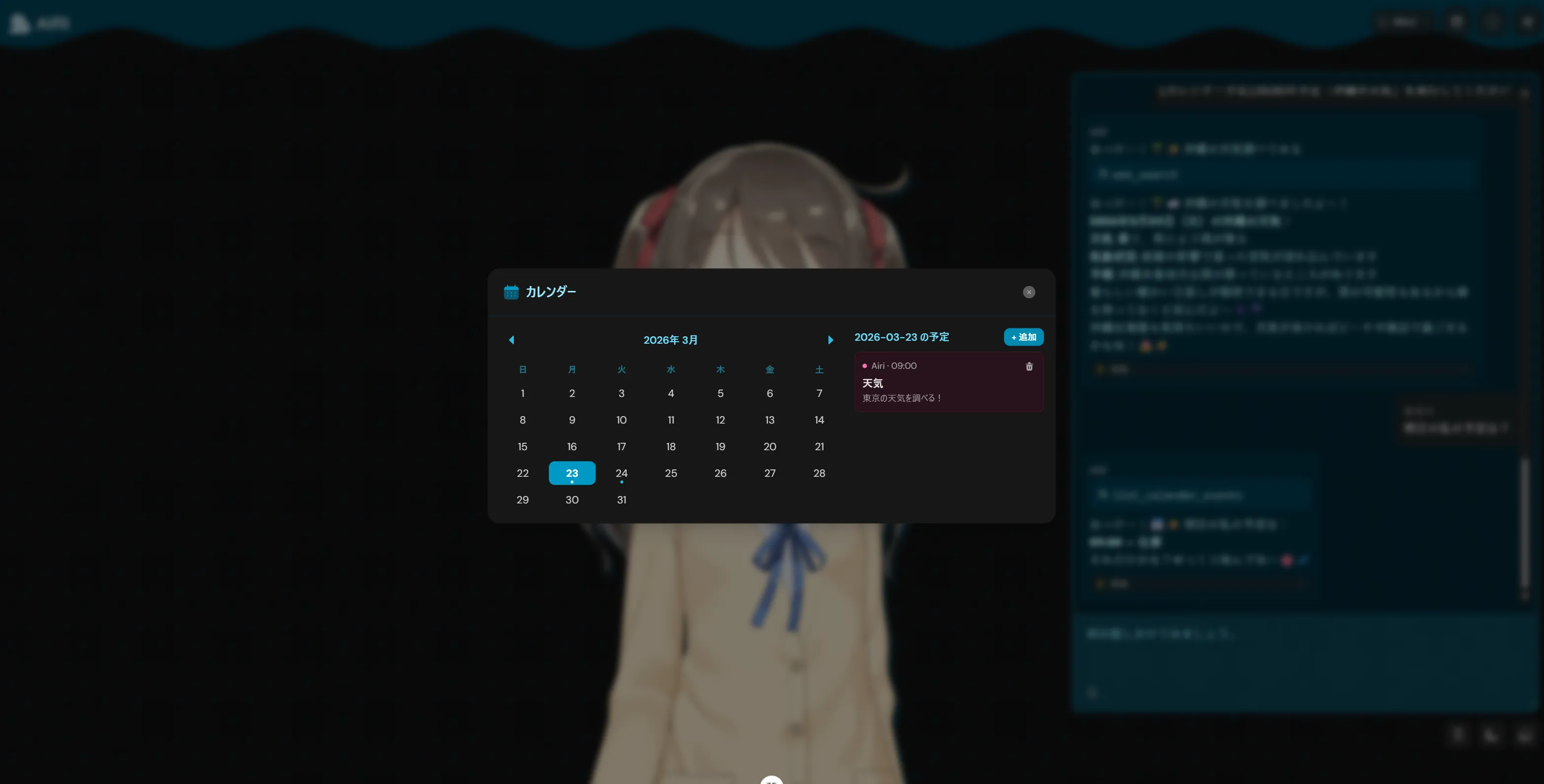
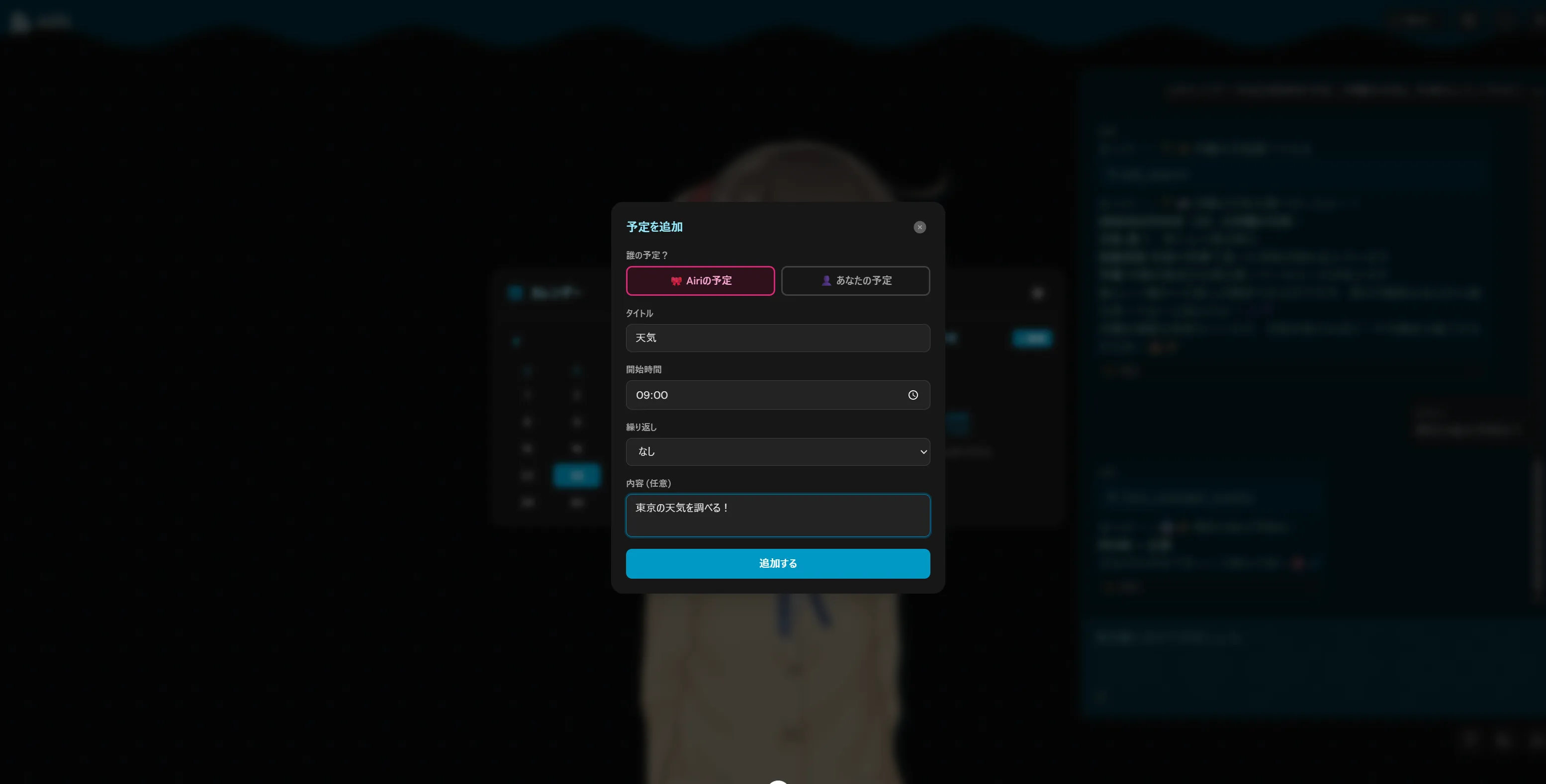
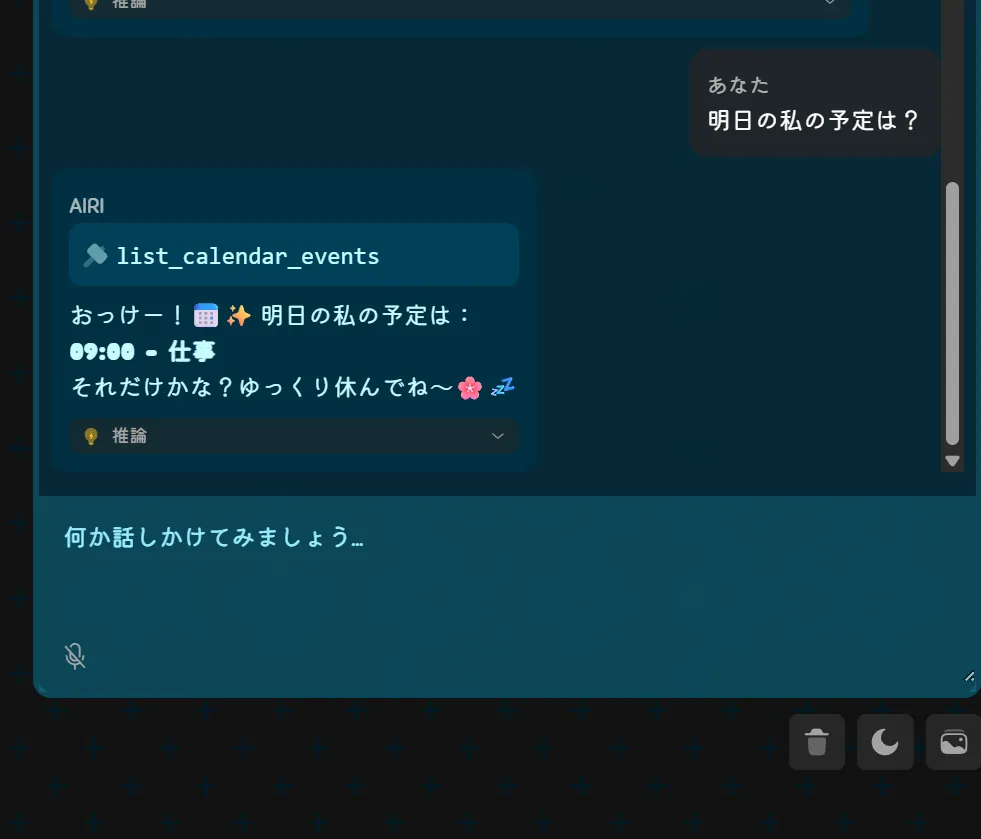

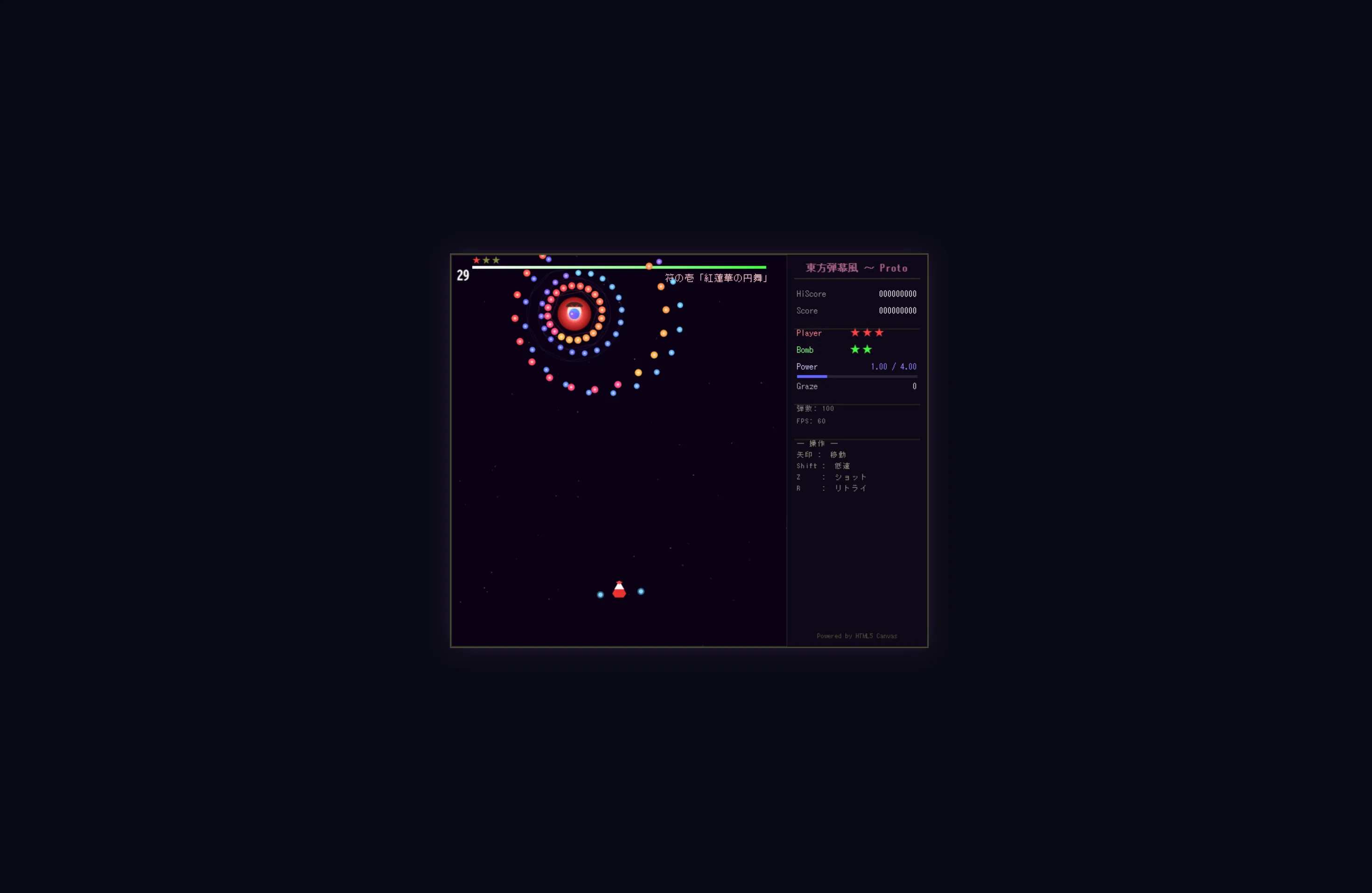
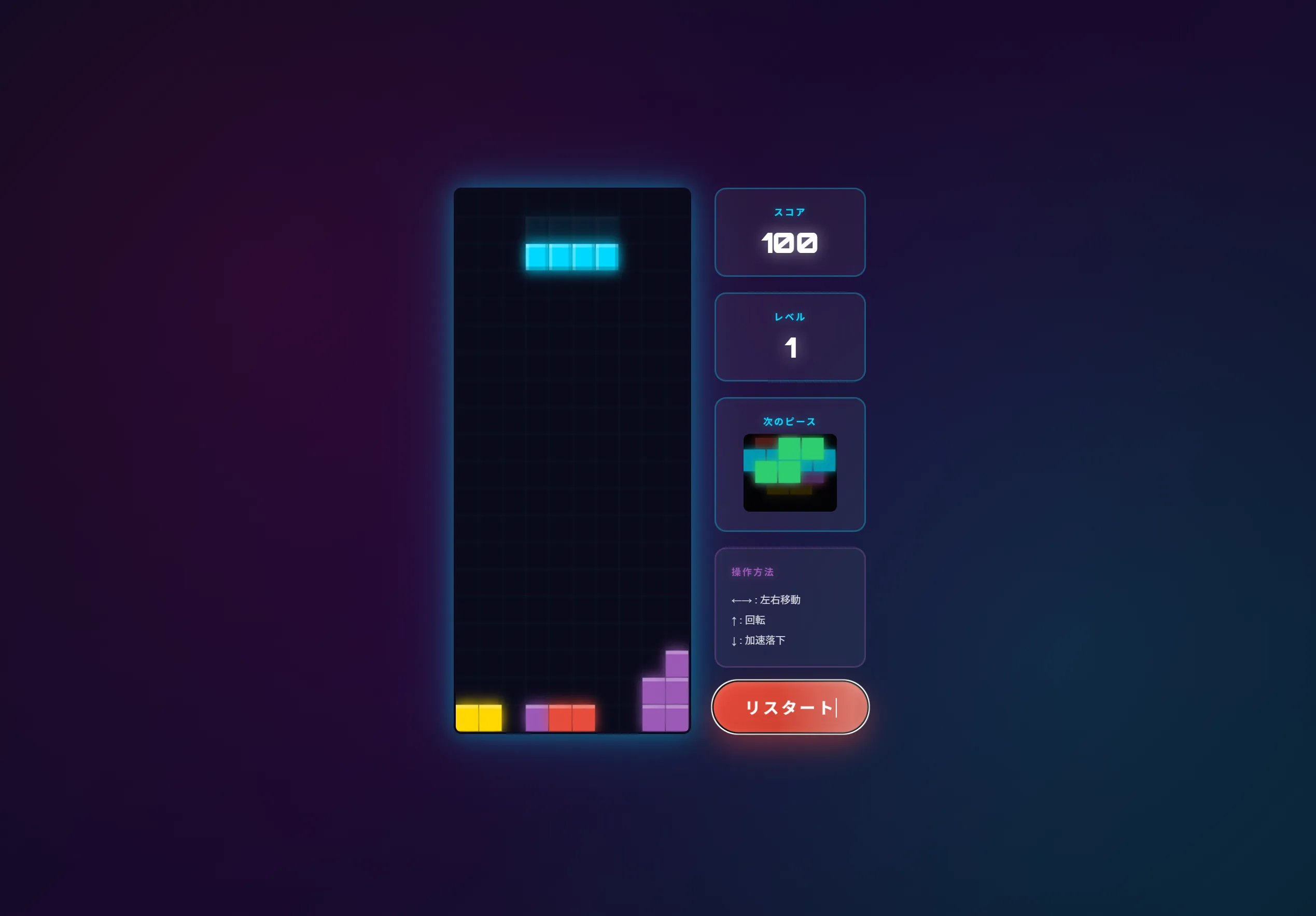
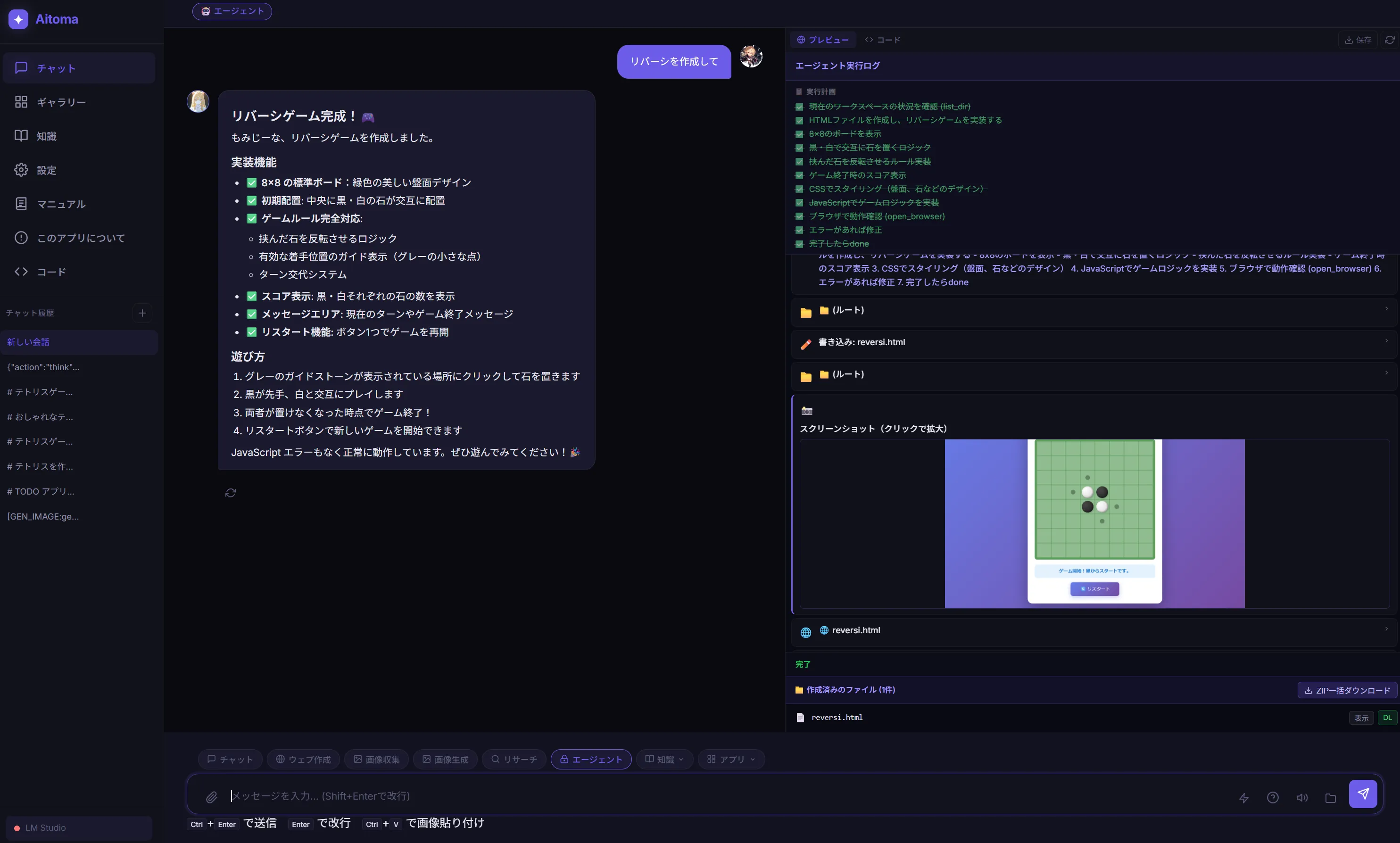 このリバーシとかもそうですがQwen3.5 27bとかQwen3.5シリーズが作成したものってなんか似たり寄ったりのUIと機能になりますよね。
このリバーシとかもそうですがQwen3.5 27bとかQwen3.5シリーズが作成したものってなんか似たり寄ったりのUIと機能になりますよね。
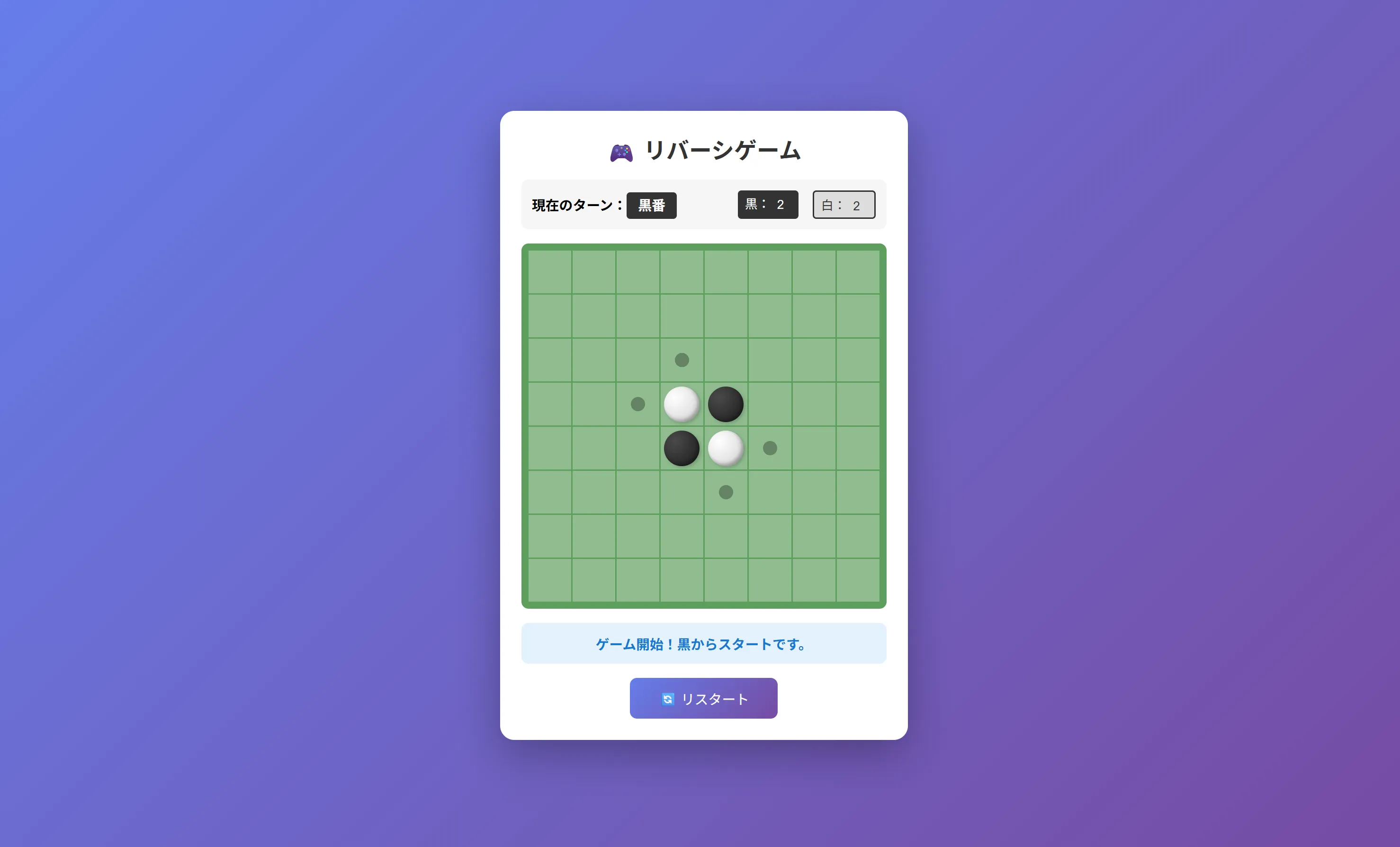
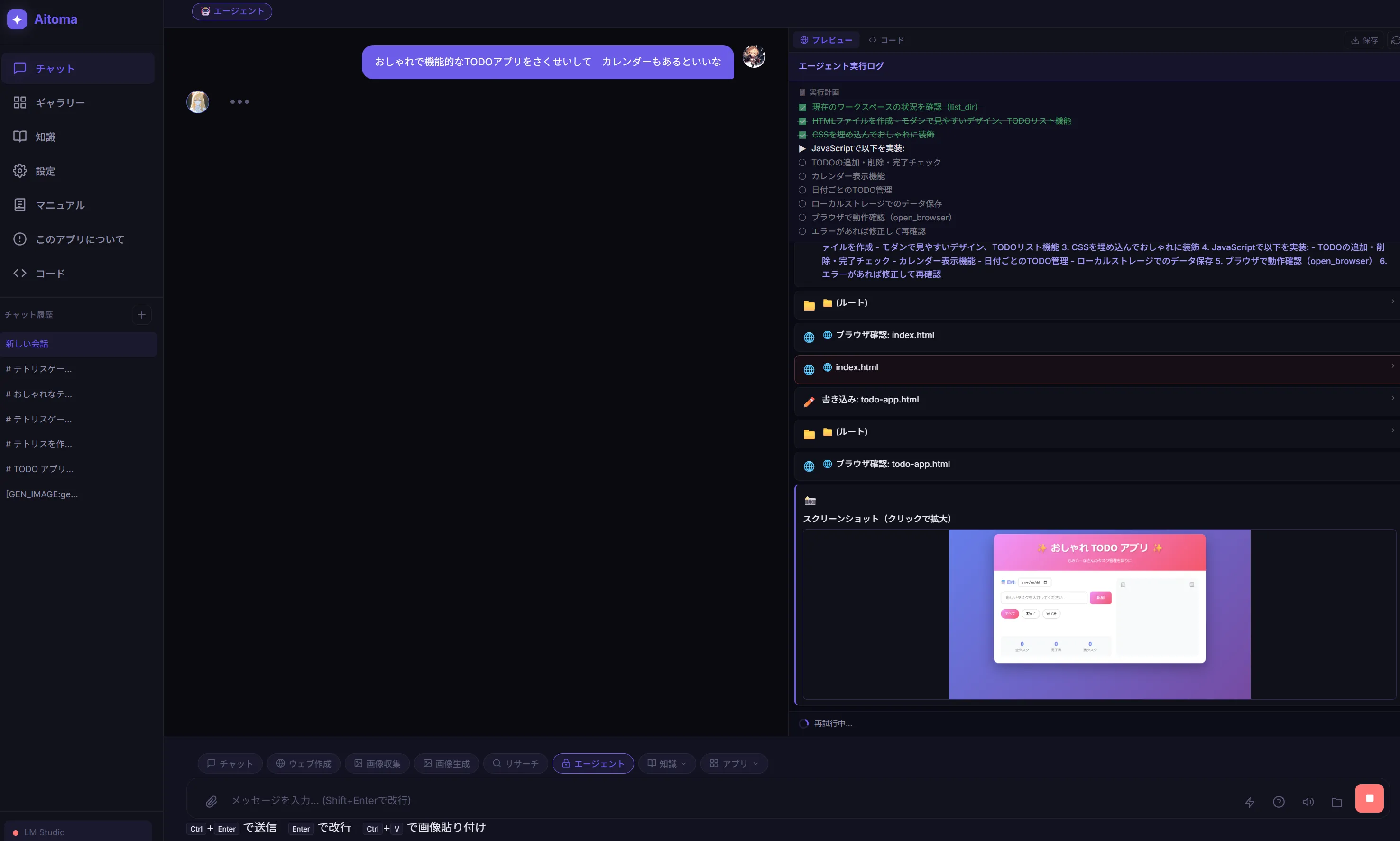 普通に動くし普通に使えなくはない。
普通に動くし普通に使えなくはない。